Når man skal samle store datamængder fra mange forskellige kilder, er Azure Event Hub et oplagt valg - det er det, den er lavet til. De enkelte services lægger deres data på hubben, hvor de så kan ligge indtil vores Function har tid til at håndtere dem.
Der er rig mulighed for at skalere hubben, så den ikke ender med at være flaskehals. Man kunne også sagtens bruge en anden besked-kø (f.eks. Azure Service Bus), men i forhold til Azures andre værktøjer er Azure Event Hub klart billigst at skalere til store datamængder.
Når beskederne fra hubben skal skrives til Data Lake, er det omkostningerne, der er den primære faktor, man bør være opmærksom på. Azure Data Lake er en billig måde at opbevare store mængder data, men prisen for at skrive til og læse fra Data Laken kan godt eksplodere, hvis man ikke er opmærksom.
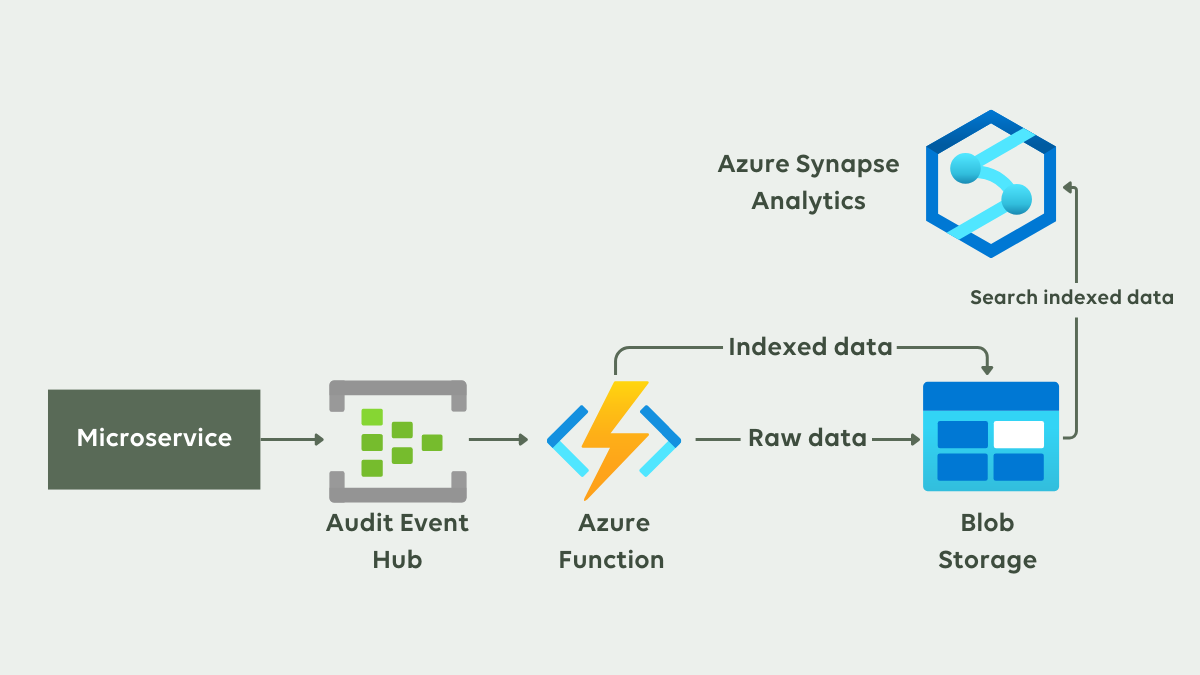
Her ser du et overordnet diagram over dataflowet i løsningen. Data bliver fanget på vej ind i, eller ud af, en microservice. Disse data kører gennem en Azure Event Hub, hvorfra det behandles af en Azure Function. Function’en sørger for at lagre de rå data, men gemmer også data i indekseret form. Begge dele bliver gemt i Azure Data Lake. I den indekserede data kan vi herefter lave søgninger med Azure Synapse Analytics.
